YOLO는 CNN 기반의 대표적인 객체 탐지 모델
※ 이 글에서는 yolo에 대한 깊은 설명은 하지 않습니다. (다른 분들이 충분히 잘 정리한 글들이 많습니다)
자료 및 정리 글
1. YOLO 구조

- YOLO의 논문에 의하면 전체 구조는 사진과 같이 생겼습니다. 다만 위 글에 언급되어 있는 것과 같이 사전 학습은 224x224 해상도로 하고, 실제 객체 탐지에서는 448x448 해상도로 진행을 했다고 합니다.
- 24개의 Convolution Layer와 2개의 Fully connected layer로 구성되어 있습니다. (그림은 생략된 부분이 많습니다)
2. YOLO 동작 과정
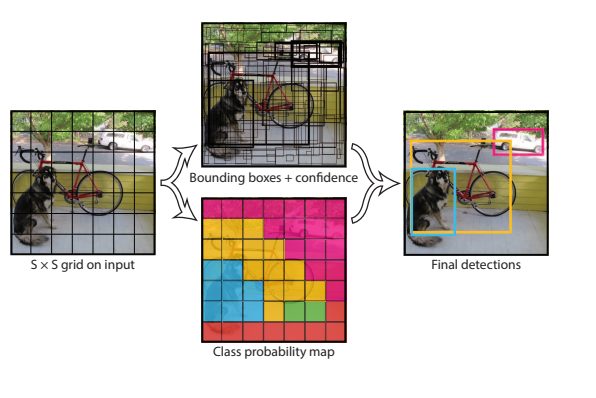
- YOLO는 S x S 크기로 나눠진 각 셀 만큼의 출력값이 나옵니다. ( S × S × (B ∗ 5 + C)개 )
- S × S : 그리드의 셀 수
- B : 셀 당 예측할 박스의 수
- 5 : x,y,w,h,confidence
- C : 클래스 수
- 저는 이 그림과 논문을 읽고 "어떻게 각 셀은 객체 탐지를 하는가?" 라는 궁금증이 생겼습니다.
- CNN의 특징을 생각하면 됩니다. CNN은 커널 연산을 통해 특징 맵을 얻습니다. 그 특징맵은 각 셀의 특징이 아닌 주변까지 포함하기 때문에 수용 영역(Receptive Field)는 점점 커지게 됩니다. 또한 MaxPooling으로 더욱 그 영역은 커지게 됩니다. 그래서 작은 크기의 커널임에도 MaxPooling + LayerStack으로 인해 각 셀은 큰 영역에 대해 탐지를 할 수 있게 됩니다.
- YOLO는 왜 기존 CNN 기반 객체 탐지 모델보다 처리 속도가 빨랐을까?
- 기존의 모델과 다른 End-to-End 구조입니다. (한번에 박스와 클래스를 예측)
- 1x1 Conv Layer의 역할(1번은 제가 기존의 모델 구조를 잘 몰라서 크게 와닿지 않았고, 이 부분에서 왜 빠른지 이해가 됐습니다.)
- YOLO의 전체 구조 사진을 보면 3x3과 1x1 크기의 커널을 가진 Conv Layer을 사용합니다. 이는 연산량에서 엄청난 차이를 내게 하는 구조입니다. 간단한 예시를 들어보겠습니다.
- 입력 특징 맵 : 14×14×1024
- 3×3x512 Conv Layer
- 파라미터수는 3×3×1024×512= 4.7M이 되고, 연산량은 14×14×1024×3×3×512=924.8M이 됩니다.
- 그런데 먼저 1×1 conv로 채널을 줄이게 되면
- 1×1×256 Conv Layer + 3×3×512 Conv Layer
- 파라미터 수는 (1×1×1024×256=0.26M) + (3×3×256×512=1.18M) ≈ 1.44M이 되고, 연산량은 (14×14×1024×1×1×256=51.3M) +(14×14×256×3×3×512=231.2M) ≈ 282.5M이 됩니다.
- YOLO의 전체 구조 사진을 보면 3x3과 1x1 크기의 커널을 가진 Conv Layer을 사용합니다. 이는 연산량에서 엄청난 차이를 내게 하는 구조입니다. 간단한 예시를 들어보겠습니다.