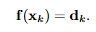
분산 데이터 보간(interpolation)은 위와 같은 연속적이고 부드러운 함수를 만드는데 목표를 갖음.
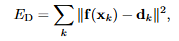
분산 데이터 근사(approximation)는 함수가 데이터 점 근처를 통과하는 것을 목표로 함.

책에는 간단한 분산 데이터 보간과 근사에 대한 알고리즘이 나옴.
보간 알고리즘에는 Delaunay triangulation, 근사 알고리즘에는 pull-push
Delaunay triangulation algorithm은 데이터를 이어서 삼각형으로 만듦.
그리고 어떤 점P가 있을때, 해당하는 삼각형 영역 내에서 각 점에 대해 가중치를 부여해 값을 계산함.
그래서 점을 정확히 통과하기 때문에 보간 알고리즘임.
pull-push algorithm은 그리드를 나누고 그리드 안에 각 데이터가 있음.
하위의 더 낮은 해상도로 데이터를 축소함. (pull)
낮은 해상도에서 높은 해상도로 전파하면서 누락된 셀들을 보완함. (push)
근처 값을 통해 평균을 내어 보완하는 방식이기 때문에 근사 알고리즘임.
4.1.1 Radial basis functions


x = 평가 지점, xk = 흩어져 있는 데이터 지점, φ = radial basis functions(or kernel), wk = 가중치
r = 반지름, c = 스케일 파라미터 (작을수록 좁고 뾰족한 곡선, 클수록 넓고 완만한 곡선)
xk는 중심
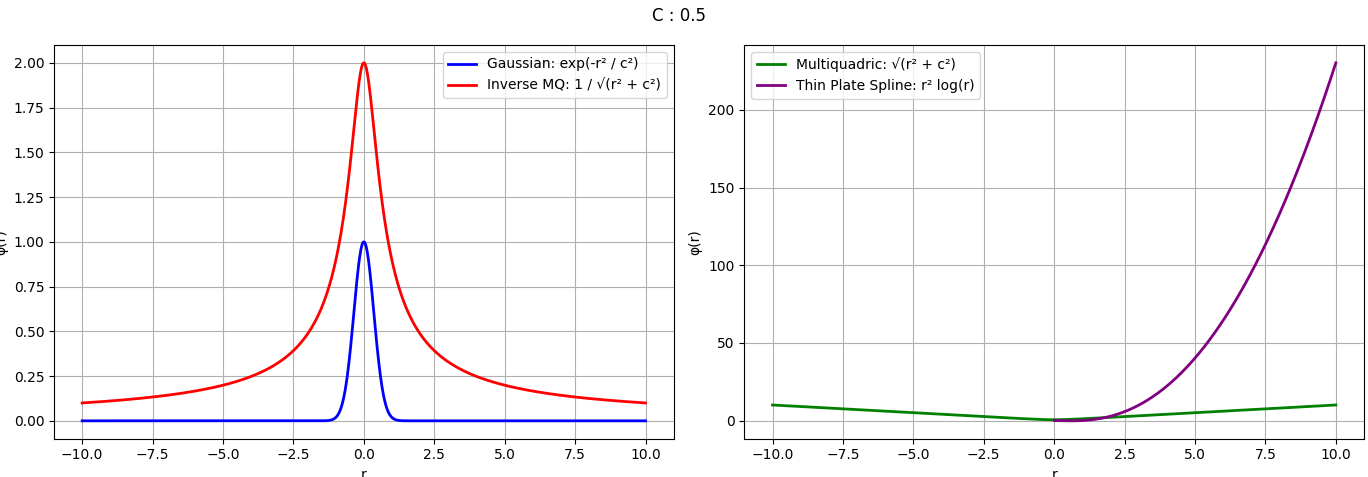

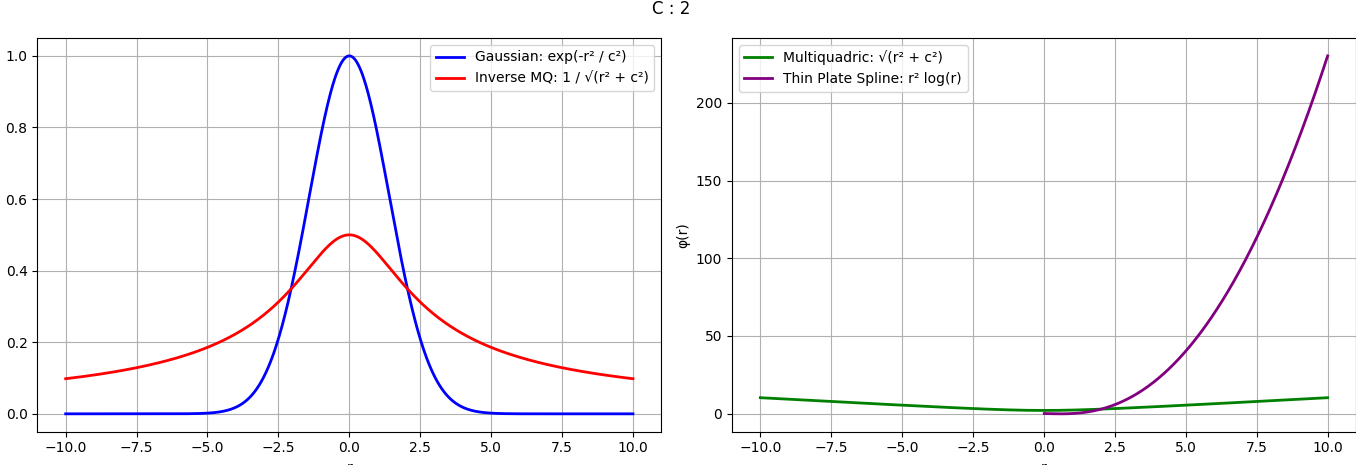
보통 사용하는 4개 radial basis function에 대한 그래프
책에서 Thin plate spline 함수는 2차원에 적용된다고 함. (이유는 접은글 확인)
TPS는 2차원 공간에서 최소 곡률 에너지를 갖는 곡면의 해임
2D 평면에 점들이 주어졌을 때, 이 점들을 정확히 통과하면서 전체 곡면의 휘어짐 에너지를 최소화하는 곡면을 구하고자함.
곡률 에너지를 최소화하는 함수가 tps 수식임.

보간 함수를 만들기 위해 선형 시스템을 풀어 가중치를 구해야함.
하지만 여기서 기저 함수(basis function)이 서로 너무 많이 겹치면 이 행렬이 ill-conditioned 될 수 있음.
또한, 이러한 선형방정식의 해는 일반적으로 O(m^3)임.
※ill-conditioned는 아주 작은 입력 변화에도 큰 출력 변화가 생기는 시스템을 의미
(rbf 함수가 넓게 퍼지면, 즉 c의 값이 크다면 기저 함수의 값은 비슷해짐. 그래서 행렬이 유사한 값들로 채워져서 선형독립성이 약화됨)

이상적으로는 어떤 점에 대한 보간 함수를 만들고 싶지만, 현실에는 노이즈, 과잉적합, ill-conditioned 등 다양한 문제 때문에 근사 + 정규화를 함. (p는 정규화 노름 차수 (1 or 2))
Ed는 xk에서의 출력이 dk에 가깝도록 데이터를 근사함.
Ew는 정규화 항임. 정규화계수(λ)의 값에 따라 의미가 달라짐.
정규화 계수가 0이면 정규화 항 자체가 사라지면서 데이터 오차만 최소화하게 됨. 즉, 과잉적합이 됨.
정규화 계수가 큰 수면 Ed항은 무시가 되고, 가중치들을 0에 가깝게 만들게 됨. 그래서 함수 자체의 출력값은 0에 가까운 상수 함수가 됨. 즉, 과소적합이 됨.
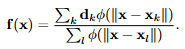
kernel regression or the Nadaraya-Watson model.
모든 커널 함수들의 합을 정규화시킴.
가까운 데이터 xk는 더 큰 영향을 주고 먼 데이터는 영향이 거의 없음.


∑kϕk′(x) = 1 (partition of unity라고 함)
ϕk′(x)는 x 위치에서 xk가 얼마나 중요한지 나타냄. 기여도 측정.
4.1.2 Overfitting and underfitting

위 사진에서 초록색 사인 함수에서 노이즈가 있는 샘플들인 파란색 점들이 있음.
여기서는 3차 다항 회귀 모델이 가장 유사하게 근사했다. 차수가 9인 모델은 노이즈가 있는 데이터에 대해 정확히 지나면서 과적합이 된 상황임.
그래서 모델의 복잡도는 너무 낮아도, 너무 높아도 안됨. 적절한 차수를 찾는 것이 중요함.
다항식의 차수가 9인 상태에서, 정규화계수(λ)의 값에 따른 결과 곡선의 차이점임.
왼쪽의 λ 값은 매우 작고, 오른쪽은 1임.
모델의 복잡도가 높기 때문에 과잉적합이 발생할 수 있음. 그래서 정규화를 통해 파라미터의 값을 조절함.
왼쪽은 정규화 항의 영향이 적기 떄문에, 모델이 데이터에 비슷하게 맞춰짐.
오른쪽은 정규화 항의 영향이 크기 때문에, 과소적합이 됨.
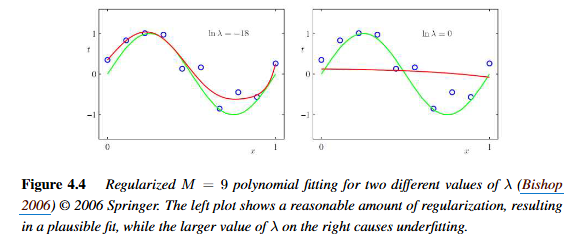
정규화의 강도에 따른 학습 데이터의 오차와 검증 데이터의 오차율 그래프임. (y축 값이 낮을수록 좋은 모델임)
과소적합은 학습 데이터를 잘 설명하지 못함. 그래서 검증 데이터도 당연히 오차가 큼.
과잉적합은 학습 데이터만 잘 설명함. 그래서 검증 데이터의 오차율은 다시 증가하게 됨.
general한 모델을 만들기 위해선 validation error가 가장 낮은 지점을 찾는 것이 핵심임.

정규화의 정도에 따른 학습 결과 함수들의 차이임.
정규화가 강하면 데이터에 따라 결과가 크게 바뀌지 않음. 편향(bias)이 크고 분산(variance)이 작음.
정규화가 약하면 데이터에 따라 결과가 크게 바뀜. 편향이 작고 분산이 큼. (bias-variance tradeoff)
그래서 적절한 λ값을 찾는 것이 중요함. (cross-validation, K folds)
4.1.3 Robust data fitting

p()는 robust loss function임.
일반적으로 사용하는 MSE는 이상치(outlier)에 민감함. 그래서 p() 함수를 써서 이상치의 영향을 줄일 수 있음.
※이상치는 대부분의 데이터 패턴에서 크게 벗어난 관측값을 의미 (튀는값)

위 사진은 다양한 robust loss functions를 하나의 수식으로 표현한 함수를 시각화한 그래프임.
왼쪽은 손실 함수의 그래프, 오른쪽은 왼쪽의 도함수에 대한 그래프임. (손실함수의 기울기)
x는 잔차(residual), α는 형태 조절 파라미터, c는 스케일 파라미터
α 값에 따라 손실 함수가 달라짐.
도함수의 그래프를 보면 α = 2 일때, 기울기는 선형적으로 증가함. 이상치의 영향이 크다는 의미임.
α <= 0 들의 그래프를 보면, 큰 오차에 대해 업데이트 크기가 작음. 이상치의 영향이 작다는 의미임.