5.2.2 K-means and Gaussians mixture models
군집화(clustering) 알고리즘 2가지에 대한 아이디어를 확인함.

K-means clustering (위 사진 기준으로 설명)
(a) : 2개(K)의 군집 중심을 정함.
(b) : 각 샘플들을 가까운 중심에 할당함.
(c) : 중심을 다시 계산함.
반복 후, 결정 경계 생성. 결정 경계는 두 중심 사이의 수직 이등분선임.
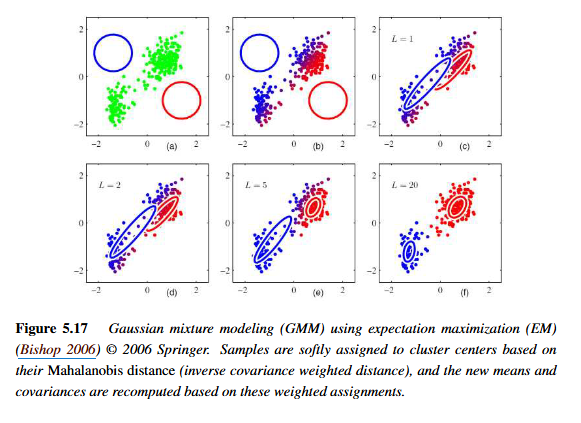
Gaussian mixture model + Expectation maximization
(a) : 2개의 원형 가우시안 분포를 생성함.
(b) : EM 알고리즘을 통해 혼합 계수, 평균, 공분산 갱신함.
(c) : 가우시안 군집 중심 이동함.
이후, 반복함.

이 수식은 각 샘플이 평균과 공분산인 파라미터의 가우시안에서 얼마나 떨어져 있는지를 측정함. (각 파라미터는 입력샘플, 군집 중심, 공분산 추정치를 나타냄)
위 수식은 마할라노비스 거리임.
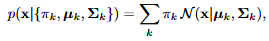

GMM 전체 확률 밀도 함수를 나타냄. 여러 개의 가우시안 분포 N을 섞음. 즉, 각 샘플에 대해 여러 가우시안 중 어디에서 나왔을 가능성이 있는지 확인함.

GMM의 파라미터는 EM 알고리즘으로 추정함. (Expectation maximization)
EM 알고리즘의 E step임. (E step에서는 책임도(Responsibility)를 추정함)
샘플 xi가 k번째 가우시안 군집에서 생성되었을 가능성에 대한 추정치임.

EM 알고리즘의 M step (책임도를 기반으로 각 가우시안의 평균, 공분산, 비율을 다시 계산함)
마지막 Nk는 k번째 가우시안에 속한 샘플 수의 기대값임.
5.2.3 Principal component analysis
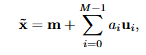

아이겐페이스 (Eigenfaces) 기법임. PCA를 이용해 얼굴 이미지의 차원 축소 및 재구성함.
여러 얼굴 이미지를 벡터 형태로 바꾸고, 그 집합에서 공분산 행렬을 구함.
공분산 행렬의 고유벡터(eigenvector)를 구함.
입력 이미지를 고유벡터의 방향으로 재구성함.

공분산 행렬에 대한 수식임.

: 공분산 행렬의 고유값임. (분산의 크기)
u : 고유벡터 (eigenfaces) → 데이터가 가장 많이 퍼진 방향

얼굴 x에서 평균 m을 빼고, 각 eigenface와 내적을 함.
ai는 스칼라값을 갖게 되고, 이 값은 얼굴이 특정 특징 방향으로 얼마나 변했는지에 대한 값임.

고유값이 내림차순으로 정렬되어 있다면, 앞부분의 고유벡터들일수록 정보량이 많고, 뒤로 갈수록 노이즈가 많음.
x에 대해 M개의 eigenface만으로 근사한다면 최적의 근사가 됨. (최소 오차)
M개의 eigenface로 표현한다는 건 고차원 이미지 공간을 선형 부분공간 F에 투영한 것임.

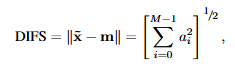
DIFS (Distance In Face Space)
face space에서 얼굴이 평균에서 얼마나 떨어졌는지 측정하는 것임.
DFFS (Distance From Face Space)
원본 얼굴이 face space에서 얼마나 벗어나 있는지를 측정하는 것임.
dffs가 크다면 얼굴이 아닐 가능성이 높음.
'Computer Vision > 5. Deep Learning' 카테고리의 다른 글
| [5.5] More complex models (1) | 2025.06.25 |
|---|---|
| [5.4] Convolutional neural networks (0) | 2025.06.13 |
| [5.3] Deep neural networks (깊은 신경망) (0) | 2025.06.08 |
| [5.1] Supervised learning (지도학습) (0) | 2025.06.02 |