
CNN은 모든 뉴런이 이전 층의 모든 뉴런와 연결된 FC layer와 다르게 합성곱(convolution) 연산을 사용함.
전체 이미지를 한꺼번에 보는 것이 아닌, 작은 지역(local window)만 살펴보며 특징을 추출함. 각 윈도우에서의 연산은 모든 위치에서 동일한 가중치를 사용함.
각 층은 여러 개의 특징 맵(Feature Map)을 출력함. 각각의 커널은 특정한 특징(수평,수직등)을 감지하도록 학습됨.
그래서 CNN의 초반부는 저수준의 특징을 추출하고, 후반부는 고수준의 특징을 추출하게 되고, 마지막은 FC layer와 softmax를 통해 최종 분류 작업을 수행함.

대부분 2D convolution은 입력 채널(C1)과 출력 채널(C2)는 다채널임. 다채널의 convolution의 각 출력 채널은 입력의 모든 채널을 동시에 사용하여 계산함. 즉, 각 입력 채널 별로 필터(커널)를 가지고 있고, 채널마다 convolution을 수행한뒤, 합산해서 하나의 출력 채널로 만듦.
그럼 커널의 가중치 수, 파라미터 수, 연산량(FLOPs)에 대해 확인해보자. ( S : 커널크기)
- 출력 채널 1개 당 필요한 커널의 가중치 수는 S^2 * C1
- 전체 conv layer의 파라미터 수는 S^2 * C1 * C2
- 한 번의 forward pass에서 연산량은 W * H * S^2 * C1 * C2

s : 출력 특징맵의 (i,j)위치, 출력채널 c2 / w : 커널의(k,l)오프셋,c1과c2용 가중치 / x : (i+k,j+l)위치, c1
CNN의 연산을 수식으로 표현함.
출력 특징맵은 해당 출력 채널 c2에 대해 모든 입력 채널 c1을 순회하며 커널의 크기만큼의 영역을 확인하며 각 입력 위치 (i+k,j+l)에 해당하는 activation 값과 가중치를 곱해서 합하고 마지막으로 bias를 더함.
하지만 엄밀히 말하면 위 수식은 correlation임.
convolution

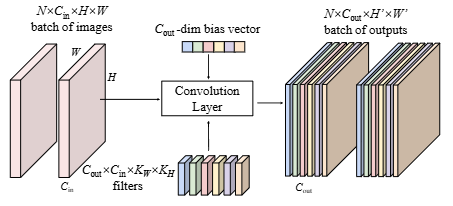
미니배치 기반으로 다채널 이미지들을 conv layer에 넣을 때, 각 출력 채널은 모든 입력 채널을 활용하여 작은 윈도우 영역을 통해 합산하고 바이어스를 더해 최종 출력 값을 만듦.
각 출력 채널마다 Kw * Kh * Cin개의 가중치를 갖고, 전체 레이어의 총 파라미터 수는 Kw * Kh * Cin * Cout임.
Conv Layer에 필요한 파라미터들
- Padding : 커널을 이미지 경계에 적용할 때 문제가 발생함. 그래서 padding 유무에 따라 출력의 크기가 달라짐.
- Stride : 커널을 얼마나 건너뛰며 적용할지에 대한 파라미터임. 2이면 가로세로 출력 크기가 절반으로 감소함.
- Dilation : 커널 내부 샘플링 지점을 건너뜀. 그래서 수용영역이 확장됨.
- Grouping : 입력 채널과 출력 채널을 여러 그룹으로 나눠서 별도로 convolution 수행함. 1이면 일반 conv임.
5.4.1 Pooling and unpooling
Pooling은 해상도 축소, shift invariance, 계산량 감소, 과적합 방지를 위한 목적으로 사용함.
Pooling은 이미지에 대한 약간의 이동에 robust하도록 설계되었다.(영역 내 여러 값을 요약하기 떄문임) 하지만 완벽한 shift invariance를 보장하지는 못한다.
- Average Pooling : 영역 내 모든 값을 통해 평균을 냄 / 다운샘플링 + smoothing
- Max Pooling : 영역 내에서 최대값만 추출함 / 다운샘플링 + 가장 강한 특징 유지
그런데 알 수 있는 점은 stride > 1인 convolution도 다운샘플링 효과가 있다. Pooling은 오직 다운샘플링만 하지만 stride conv는 특징 추출과 다운샘플링을 같이 하는 효과이다.

위 그림은 Transposed Convolution 과정에 대한 그림임.
저해상도의 입력 특징맵을 업샘플링 하기 위해 stride를 기준으로 입력 샘플 사이에 0을 삽입함.(Zero insertion / 위 그림은 stride = 2) 그리고 일반 convolution을 적용함.
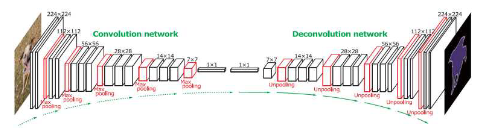
위 모델의 구조는 좌측(Convolution network / Encoder), 가운데(bottleneck), 우측(Deconvolution network / Decoder)로 구성됨.
- Encoder
- 여러 Conv + pooling layer로 해상도를 점점 줄임.
- 추상적인 high level feature를 추출함.
- Bottleneck
- 1x1 conv layer로 핵심 특징을 요약함.
- Decoder
- Transposed Convolution 사용함.
- 해상도를 점진적으로 복원하여 마지막 출력은 원래 해상도로 복구함.


위 모델은 Encoder-Decoder 구조는 동일하나 skip connection를 추가함.
Encoder는 다운샘플링, Decoder는 업샘플링을 동일하게 하지만, 같은 해상도의 encoder의 출력을 decoder에 전달함.
skip connection은 다운샘플링 과정에서 손실된 디테일을 보완하고 spatial 정보를 보존함.
5.4.2 Application: Digit classification
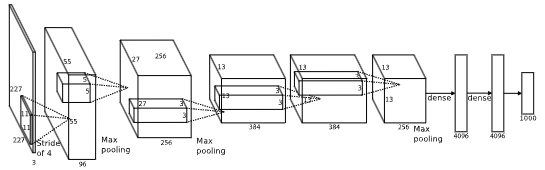
위 그림은 AlexNet의 구조를 나타냄.(Conv layer 5개 + FC layer 3개)
- Conv (11x11x96, stride = 4)
- (227 - 11) / 4 + 1 = 55 / 상하좌우에서 5씩 줄어듦
- 96개의 커널을 가지고 있으니 출력값은 55x55x96
- Conv (5x5x96x256, stride = 1) + maxpooling (3x3, stride = 2)
- Conv) 55 - 5 + 2 x 2 + 1 = 55 / zero-padding 적용
- Maxpooling) 55 - 3 / 2 + 1 = 27
- 27x27x256
- Conv (3x3x256x384, stride = 1) + maxpooling (3x3, stride = 2)
- Conv) 27 - 3 + 2 x 1 + 1 = 27
- Maxpooling) 27 - 3 / 2 + 1 = 13
- 13x13x384
※maxpooling 정보는 논문이 아닌 다른 블로그를 참고함
※위 내용은 사진만 보고 계산한 내용이므로 정확하지 않을 수 있음.
'Computer Vision > 5. Deep Learning' 카테고리의 다른 글
| [5.5] More complex models (1) | 2025.06.25 |
|---|---|
| [5.3] Deep neural networks (깊은 신경망) (0) | 2025.06.08 |
| [5.2] Unsupervised learning (비지도학습) (0) | 2025.06.03 |
| [5.1] Supervised learning (지도학습) (0) | 2025.06.02 |